Querying with SPARQL
- Last verification: 20220909
- Tools required for this lab:
- A tool for querying RDF files using SPARQL. Choose one of the two:
- [preferred] SPARQLer (a general purpose SPARQL query processor) – it is more powerful (because it implements CONSTRUCT queries) but it is less friendly because it only accepts links to RDF/XML files, so you have to prepare your document first:
- Convert your document from Turtle to RDF/XML (using tools from previous lab)
- Then host the file somewhere – we need the direct URL of this file for querying it using SPARQLer (not the URL of download page), i.e., if you are hosting the file using the Dropbox, change the www.dropbox.com to dl.dropboxusercontent.com in the sharing link, e.g.:
https://www.dropbox.com/s/kc3g05y0k7t1mbw/foaf.rdf # sharing link generated by Dropbox https://dl.dropboxusercontent.com/s/kc3g05y0k7t1mbw/foaf.rdf # direct URL for SPARQLer
- A tool for querying SPARQL Endpoints:
- [preferred] Yasgui (Yet Another Sparql GUI) – it has more powerful editor than RDFShape (but it can't be used against simple RDF files)
- Not required, but can be useful: SPARQLer Query Validator
Prepare yourself for the lab
- If you missed the lecture about SPARQL, at least watch the video: SPARQL in 11 minutes
Lab instructions
At the end of the lab, each group should email their first project to the teacher. It consist of:
- a list of the names of all project authors,
- the final
*.ttlfile with the graph developed during the previous lab, - the set of SPARQL queries against the knowledge graph developed during today's lab (up to Section 4. ASK and DESCRIBE queries).
1. SPARQL = Pattern matching [20 minutes]
- General Idea: SPARQL is an RDF graph pattern matching system.
- E.g.: there is a triple saved in RDF:
:Hydrogen :standardState :gas .
- Now we can simply replace part of the triple with a question word (with a question mark at the start) and we get simple queries, e.g.:
- Query:
:Hydrogen :standardState what? .
Answer::gas - Query:
?what :standardState :gas .
Answer::Hydrogen - Query:
:Hydrogen ?what :gas .
Answer::standardState
- Do you have your knowledge graph, developed during the previous lab? If not, now is the time to find it!
- Open the preferred tool for querying RDF files using SPARQL (see Tools required for this lab at the top of this page) and execute your first simple SELECT query against your knowledge graph:
SELECT ?a ?b ?c WHERE { ?a ?b ?c } LIMIT 10
- Now, it's time to explore your graph more! Prepare two queries for your graph that extract some interesting information. Use only triple patterns – we will move to more complicated things in the subsequent sections.
- If you want to ask about all members of a container, you can use the
rdfs:memberwhich is equivalent to allrdf:_1,rdf:_2, … relations, e.g.:BASE <http://example.org/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?who ?place WHERE { ?who <visited> [ a rdf:Bag ; rdfs:member ?place ] } LIMIT 10
selects all pairs of people and places visited by them (can be executed against
https://krzysztof.kutt.pl/didactics/semweb/bob_and_mona_lisa.rdffile) - SPARQL 1.1 Query Language may be useful.
- Save the queries for the report!
2. Constraints: FILTER [15 minutes]
After matching RDF graph pattern, there is also possibility to put some constraints on the rows that will be excluded or included in the results. This is achieved using FILTER construct. Let's try it now on your knowledge graphs.
- Your graph should contain at least a few different datatypes (this was a requirement in a previous lab!). Select two of them (e.g., boolean, string, numeric, date) and check what functions can be used in filters for them.
- List of SPARQL Filter Functions – quite good as a short reference
- Prepare and execute two queries (one for each selected datatype) that filter something interesting in your knowledge graph.
- Save the queries for the report!
3. SPARQL as rule language [15 minutes]
So far, we have seen that the answers to questions in SPARQL can take the form of a table. In this section, we will take a look at CONSTRUCT queries which answers take the form of an RDF graph. They provide a way to introduce “rules” into RDF datasets:
- Let's back to the model you prepared previously. Probably you had a problem which relations should be placed in RDF file:
is_father_oforis_child_ofor maybe both of them? - CONSTRUCT queries make this simpler. In the initial data set you can put one of them, let's assume it was
is_father_of. Now, you can execute CONSTRUCT query that creates inverse relation:PREFIX bb: <http://yourname/b-and-b#>. CONSTRUCT { ?child bb:is_child_of ?father . } WHERE { ?father bb:is_father_of ?child }
- Or maybe
is_uncle_ofrelation will be useful? No problem!PREFIX bb: <http://yourname/b-and-b#>. PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> CONSTRUCT { ?uncle bb:is_uncle_of ?child . } WHERE { ?uncle bb:is_sibling_of ?parent; a bb:Man. ?child bb:is_child_of ?parent }
- OK, we created some new RDF triples using CONSTRUCT query. What now? Depending on your plans, you can:
- Add these triples back to the original dataset,
- Create new dataset (e.g., save results in RDF file).
- And then simply execute queries against this new knowledge.
- Note: there are more powerful ways to define rules in knowledge graphs – we will explore them later.
- Now, it's time for you to develop 2 CONSTRUCT queries that provide useful rules for your knowledge graph!
- Save the queries for the report!
4. ASK and DESCRIBE queries [15 minutes]
SPARQL also provides two more query types:
- ASK queries simply provide Yes/No answer and no information about founded triples (in case of “Yes” answer).
- DESCRIBE queries return all knowledge associated with given Subject URI(s).
- Prepare at least one ASK query that checks something interesting in your knowledge graph.
- Prepare at least one DESCRIBE query that describe the most interesting “thing” in your knowledge graph.
- Save the queries for the report!
5. DBpedia SPARQL Endpoint [30 minutes]
SPARQL queries may be asked against RDF file as we did in previous sections. But there is also possibility to use special purpose web services called SPARQL Endpoints. As we already know Wikidata, we will explore the DBpedia in this section.
- Do you remember your task from the first lab? You were asked to prepare a list of the 15 most populous countries in Europe based on Wikipedia. Now we know enough to not do it manually but use the SPARQL language and DBpedia instead!
- As DBpedia is a dump of Wikipedia, it should contain some information about Poland. We don't know what URI Poland has in DBpedia, but we know the name Poland, and we remember that
rdfs:labelproperty is useful. Maybe this will help us? Let's try! - Open the preferred tool for querying SPARQL Endpoints (see Tools required for this lab at the top of this page).
- Enter
http://dbpedia.org/sparqlas SPARQL Endpoint. - What we know so far? There should be some URI (
?country) that probably has a relationrdfs:labelwith object“Poland”@en. This can be easily translated into SPARQL query:PREFIX dbo: <http://dbpedia.org/ontology/> PREFIX dbr: <http://dbpedia.org/resource/> PREFIX dbp: <http://dbpedia.org/property/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT ?country WHERE { ?country rdfs:label "Poland"@en . }
- Hint: some useful prefixes are already in place to assist you in this task.
- Success! Now, we can expand this query to find information about the population of Poland.
- Hint: the following line may be useful to get only objects that are numbers (like population)
FILTER(ISNUMERIC(?val))
- Now, prepare the actual query that returns a list of 15 countries in Europe with the biggest population!
6. Aggregation [30 minutes]
- SPARQL provides grouping and aggregation mechanisms known from SQL:
- grouping: GROUP BY
- aggregation: COUNT, SUM, MIN, MAX, AVG, GROUP_CONCAT, and SAMPLE
- filter on groups: HAVING
- See SPARQL 1.1 documentation for wider description.
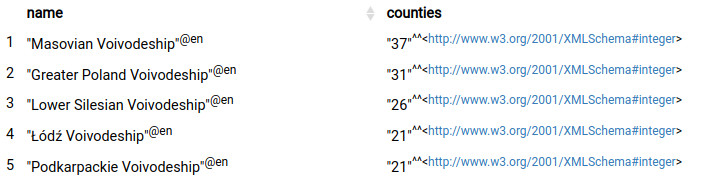
- Poland is divided into 16 voivodeships (PL: województwo), and then into 314 counties (PL: powiat). In this task, we will examine it closer.
- Prepare a query (using preferred tool for querying SPARQL Endpoints, against DBpedia) which returns list of voivodeships and number of counties inside them. List should consist only of voivodeships with 20 or more counties and should be ordered by number of counties.
- Results should look like that:

- Hint – useful URIs (you can use
dbo,dbranddbpprefixes defined in previous section):- county:
dbr:Powiat - voivodeship:
dbr:Voivodeships_of_Poland
Learn more!
SPARQL:
- You can combine results from many SPARQL Endpoints in one query – see SPARQL Federated Query for more information.
Sample queries in SPARQL:
Tools:
- SPARQLer – general purpose tool for executing SPARQL queries
- YASGUI – online visual tool for querying SPARQL Endpoints
-
- Data query – to execute SPARQL queries against RDF files
- Endpoint query – to execute queries against SPARQL Endpoints
- GeoSPARQL – standard for representing and querying the geospatial data using RDF
DB2RDF (RDF and Relational Databases):